
Introduction: From Idea to Intelligent Application
Hello, everyone!
If you read my last blog post, you know I’ve been diving deep into the world of Retrieval-Augmented Generation (RAG). I’ve decided to commit to a blog series, documenting everything I'm learning—from the foundational tools to the final deployment. This first post is dedicated to the core framework that makes modern RAG possible: LangChain.
What is LangChain? The Layer of Abstraction

Imagine you are building a RAG application. The first step is data extraction, which is usually document parsing in my case. For a noob like me, typically that means dealing with a PDF or a .docx file. Whenever a user provides some form of data, that data has to be parsed and then dealt with.
But how do I parse the data? Am I going to write my own custom PDF parser from scratch? Or can I simply use some reliable PDF parser library? This is where LangChain comes in.
Imagine you also have to create embeddings, store them in a Vector Database, connect a SQLite DB for metadata, and so on.
Rather than using separate, disparate libraries or writing your own custom wrapper functions for every single task, what you can do instead is simply use LangChain. It provides a unified set of methods and interfaces for all these components.
At its core, it's a layer of abstraction above everything—just like React.js is over raw HTML/CSS—providing a standard, predictable, and reusable way to work with the underlying complexities of the LLM ecosystem.
You'll find its components separated across langchain-community, langchain-core, and langchain, available in both Python for our Python friends and JS/TS for my Node nerds.
That's what LangChain does for us at a high level. Now, let’s explore how it solves the toughest challenges in AI application development.
How LangChain Exactly Solves the Fragmentation Problem?
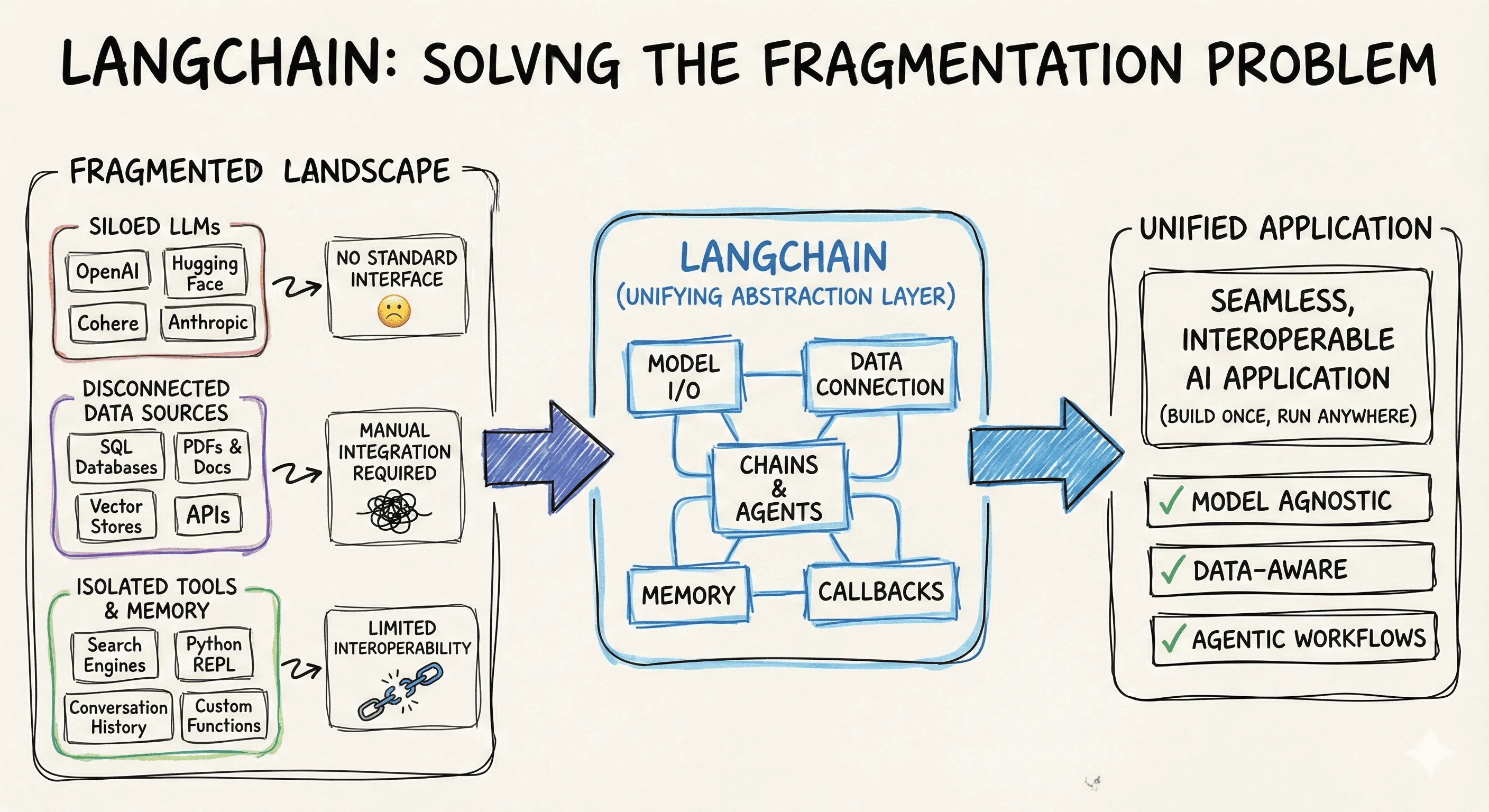
We established that building a complex AI application, like a RAG system, requires juggling 5 to 6 different tasks—from data parsing to the final LLM call. LangChain solves this chaos by providing standardized interfaces and composable components for every step of that journey.
It transforms a messy, multi-library workflow into a clean, unified pipeline.
1. The Data Ingestion Nightmare Solved: Document Loaders
Let's go back to your document parsing problem.
If you had to handle a mix of customer data—some in Google Drive PDFs, some in Notion databases, and some from a corporate Slack channel—you would need three separate Python libraries, three sets of API keys, and three custom functions to extract the raw text.
- The LangChain Solution: The Document Loader interface.
LangChain abstracts all that complexity. Instead of writing a parser for a PDF using pypdf, you simply call the LangChain component (PyPDFLoader). Instead of writing a scraper for a website, you use the WebBaseLoader.
The key isn't just that these loaders exist; it's that they all output a single, universal data type: the Document object. This object consistently contains two things:
-
page_content: The extracted text. -
metadata: Crucial context like the file name, source URL, or page number.
Because the data is standardized, the next step in your RAG pipeline doesn't care if the text came from a PDF or a website—it just knows it has a LangChain Document to process.
2. The Context Window Challenge Solved: Text Splitters
Once the document is loaded, you face the second major problem: The entire 500-page PDF won't fit into the LLM's context window (the maximum amount of text the model can process at one time). Plus, embedding a single massive document makes the retrieval inaccurate.
- The LangChain Solution: Text Splitters and Embeddings.
You need to chop the document into small, semantically meaningful chunks. LangChain offers robust text splitters (like the recommended RecursiveCharacterTextSplitter), which intelligently breaks the text not just by character count, but by common separators like paragraphs (\n\n), newlines (\n), and sentences.
These splitters guarantee three things:
-
Context preservation: They try to keep related sentences together.
-
Chunk Overlap: They allow a small overlap between chunks to prevent losing semantic context at the boundaries.
-
Standardization: The output is a list of smaller
Documentobjects, ready for the next step: embedding.
You then use LangChain's Embedding interface, which, again, provides a standard .embed_documents() method regardless of whether you’re using OpenAI, Google, or an open-source model.
3. The Workflow Coordination Solved: Chains and LCEL
How do you automate the flow from the user's question to the final answer?
The whole process—loading the document, splitting, embedding, storing in a vector DB, retrieving the relevant chunks, and sending it all to the LLM—is a multi-step workflow.
- The LangChain Solution: Chains and LangChain Expression Language (LCEL).
LangChain’s primary job is to chain these components together into a single, seamless pipeline.
-
Retrieval Chain: You define a retrieval component (
.as_retriever()) that abstracts the Vector DB complexity. -
Prompt Chain: You define a
PromptTemplatethat correctly injects the retrieved documents (the context) alongside the user's question. -
LLM Chain: You define your
ChatModel.
Using the LangChain Expression Language (LCEL), you can write the entire complex RAG workflow like a simple Unix pipe command:
retriever | prompt | llm
This single line tells the application: "Take the input, pass it to the retriever to get the documents, pass the documents into the prompt template, and send the final prompt to the LLM."
This level of abstraction and composability is the true power of LangChain. It makes complex, multi-step LLM reasoning predictable, testable, and reusable—allowing us to focus on the intelligence rather than the plumbing.
Implementation: The Transition to Production
We've established that LangChain is the necessary abstraction layer—the operating system—that turns scattered LLM components into a coherent, manageable system. But how do we actually move these concepts from a prototype to a reliable, production-ready application that can handle high load and concurrency?
The implementation journey in LangChain has mirrored the framework's own evolution, moving from simple, black-box Python classes to a highly flexible, declarative graph architecture.
From Boilerplate Crisis to Composable Components
In the early days (what the white paper calls "Classic LangChain"), the implementation centered on rigid, specialized classes like LLMChain or RetrievalQA. This solved the immediate Boilerplate Crisis by providing pre-packaged solutions for common tasks.
However, as applications grew more complex—needing streaming, asynchronous execution, and automatic parallelization—these rigid classes became a major friction point. Customizing their internal behavior was difficult, often requiring developers to inspect the source code or resort to messy workarounds.
This realization led to the most significant architectural breakthrough in LangChain's history: the creation of the LangChain Expression Language (LCEL).
The Syntax Revolution: LangChain Expression Language (LCEL)
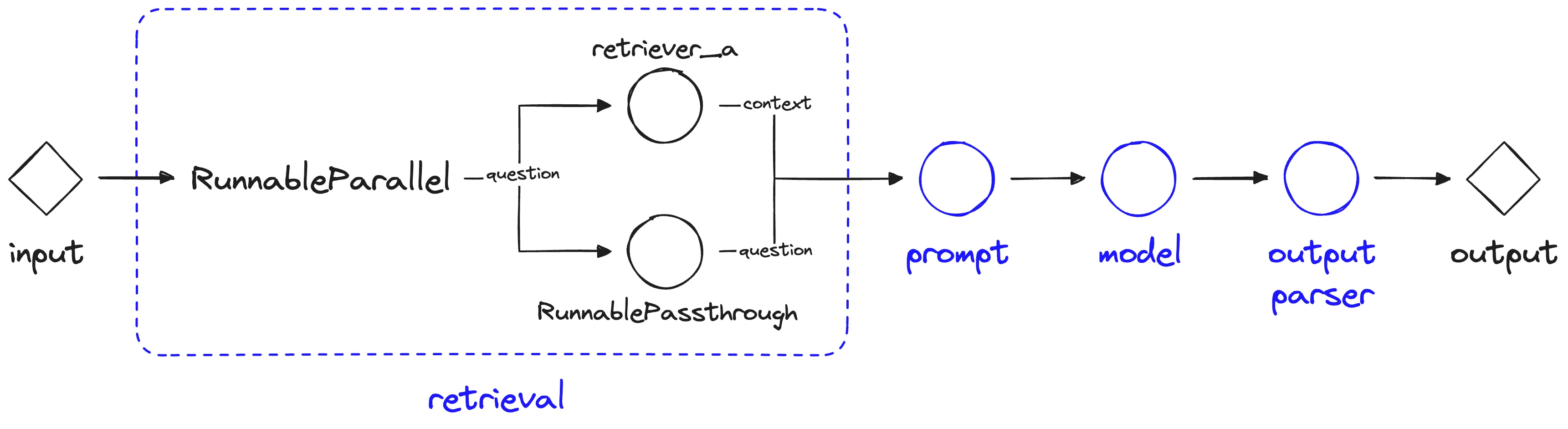
LCEL is not just a new syntax; it represents a fundamental shift in how we define and run our AI application workflows. It moves LangChain from an imperative (tell the computer exactly how to execute) framework to a declarative (tell the computer what to achieve) framework.
The result is code that is simpler to read, easier to debug, and automatically optimized for modern production needs.
1. Declarative Composition: The Unix Pipe Analogy
The core of LCEL is the pipe operator (|), borrowed from the Unix command line, which allows developers to chain components together in a readable, linear flow.
| Old Syntax (Imperative) | New Syntax (LCEL / Declarative) |
| --- | --- |
| chain = LLMChain(llm=model, prompt=prompt) | chain = prompt |
| result = chain.run("input") | result = chain.invoke("input") |
This simple syntax revolution dramatically improves readability. It explicitly defines the data flow: the input (from the user) flows into the prompt, the formatted prompt flows into the model (LLM), and the raw text from the model flows into the output_parser for clean data extraction.
2. The Runnable Protocol: Guaranteeing Consistency
To make LCEL work, every component in the LangChain ecosystem—whether it's an LLM, a Prompt Template, a Retriever, or an Output Parser—must adhere to the Runnable Protocol.
This protocol is a strict contract that unifies the entire ecosystem. Any component that adheres to it guarantees the availability of a standard set of methods:
| Method | Purpose | Key Benefit |
| --- | --- | --- |
| .invoke(input) | Synchronous (blocking) execution. | Standardized single-call execution. |
| .stream(input) | Streams the output token-by-token. | Crucial for UX: Real-time generation improves Time-To-First-Token (TTFT). |
| .batch(inputs) | Processes a list of inputs simultaneously. | Efficiency for bulk processing and reporting. |
| .ainvoke(), .astream(), etc. | The asynchronous (non-blocking) versions. | Enables high-concurrency for web servers (e.g., FastAPI). |
By adopting this protocol, LangChain makes streaming and asynchronous execution first-class citizens. You no longer need custom code or complex "Callback Handlers" to stream tokens; you just call .stream().
3. Automatic Parallelism: Latency Reduction
Perhaps the most profound benefit of defining chains declaratively with LCEL is the ability to leverage automatic parallelization.
In a complex agent, you might need to perform two independent tasks simultaneously (e.g., fetching the user's conversation history and retrieving relevant documents from a vector store). Since these two steps don't depend on each other, they can run at the same time.
Because the chain is defined clearly with | and other combinators, the LangChain runtime can inspect the entire workflow graph. If two operations can execute concurrently, the runtime automatically handles the parallel execution for you, significantly reducing end-to-end latency without requiring the developer to write complex Python asyncio.gather code. This "compilation" of the chain is a massive leap toward production-grade performance.
The Next Frontier: LangGraph and LangSmith
While LCEL gave us incredible control over linear chains (A $\rightarrow$ B $\rightarrow$ C), real-world, autonomous AI agents are messy. They need to loop, they need to branch, and they sometimes need to wait for a human. Furthermore, when they break, we need to know why in a non-deterministic world.
This is where LangGraph and LangSmith step in.
-
LangGraph: This tool is an extension of LangChain that enables cyclic workflows and state management, allowing us to build true AI agents that can loop, reason, and make complex decisions until a goal is achieved.
-
LangSmith: This is the observability and testing platform that acts as an "X-ray" for your entire LLM application, providing tracing, latency analysis, and LLM-as-a-Judge evaluation to turn black-box failures into debuggable, predictable issues.
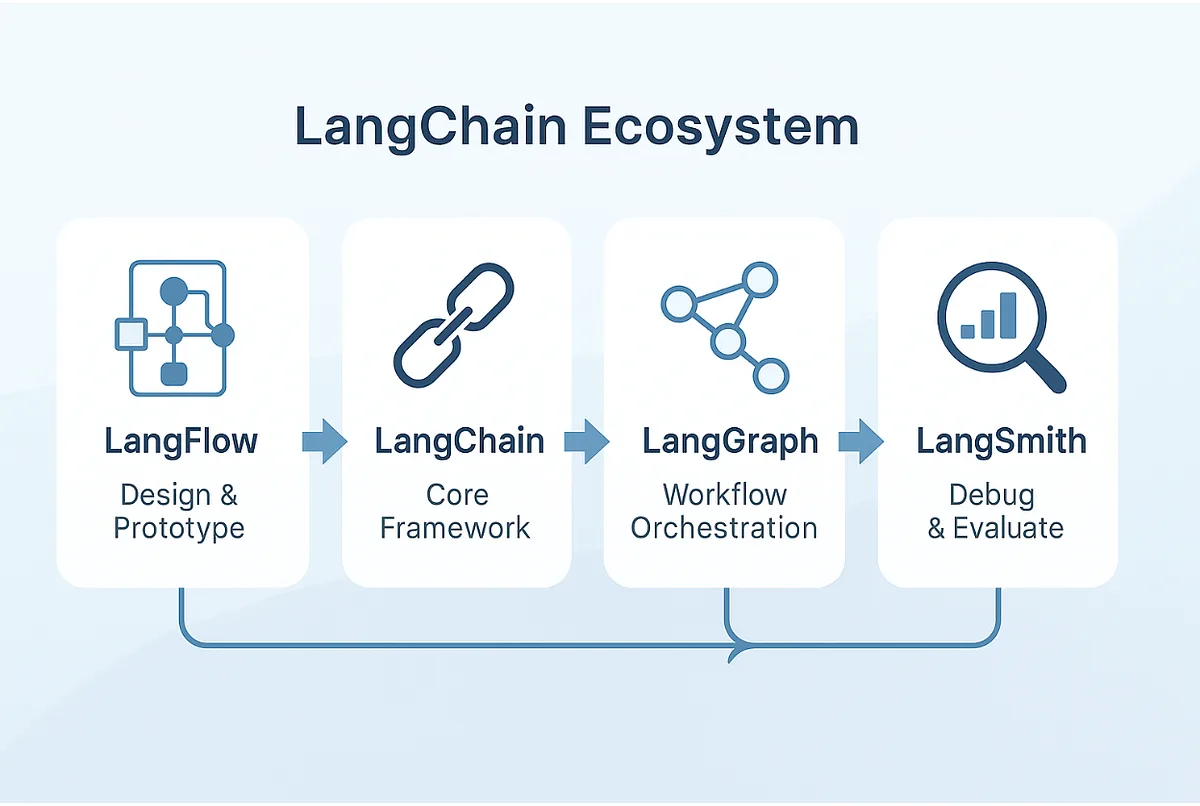
Simply put, if LangChain is the modular engine and components for your AI application, LangGraph is the flexible blueprint and state-aware architecture that defines the complex journey and decision loops, and LangSmith is the entire diagnostic dashboard, allowing you to debug, test, and assure the quality of your intelligent system.
Conclusion and What's Next: Mastering the RAG Architecture
We have established that LangChain is the necessary abstraction layer for building complex AI applications. It transforms the chaotic process of RAG implementation into a series of predictable, manageable steps. In our next post, we will move beyond the basics, leveraging this foundation to explore and implement Advanced RAG techniques such as Query Transformation, Contextual Compression (Reranking), and specialized Indexing Strategies, which are essential for building truly high-precision, production-grade agents.
See ya!
